Caching
RESTHeart Cloud🔧 Configuration
⚡ Setup Guide
To run the examples on this page, you need a RESTHeart instance.
Option 1: Use RESTHeart Cloud (Recommended)
The fastest way to get started is with RESTHeart Cloud. Create a free service in minutes:
-
Sign up at cloud.restheart.com
-
Create a free API service
-
Set up your root user following the Root User Setup guide
-
Use the configuration panel above to set your service URL and credentials
|
Tip
|
All code examples on this page will automatically use your configured RESTHeart Cloud credentials. |
Option 2: Run RESTHeart Locally
If you prefer local development, follow the Setup Guide to install RESTHeart on your machine.
|
Note
|
Local instances run at http://localhost:8080 with default credentials admin:secret
|
RESTHeart speeds up the execution of GET requests to collections, i.e. GET /coll, via caching.
This applies when several documents need to be read from a collection and can moderate the effects of the MongoDB cursor.skip() method that slows down linearly.
RESTHeart allows to Read Documents via GET requests on collections.
cURL
curl -i -X GET "[RESTHEART-URL]/coll?cache&page=3&pagesize=10" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http GET "[RESTHEART-URL]/coll" \
Authorization:"Basic [BASIC-AUTH]" \
cache==true \
page==3 \
pagesize==10JavaScript
fetch('[RESTHEART-URL]/coll?cache&page=3&pagesize=10', {
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => response.json())
.then(data => {
console.log('Retrieved documents:', data);
})
.catch(error => console.error('Error:', error));[
{ "DOC30": "..." },
{ "DOC31": "..." },
...
{ "DOC39": "..." }
]Documents are returned as paginated result sets, i.e. each request returns a limited number of documents.
Pagination is controlled via the following query parameters:
-
page: the range of documents to return -
pagesize: the number of documents to return (default value is 100, maximum is 1000).
In the examples above:
-
cacheenables cursor caching (the actual topic of this page).
Use count only when the client needs documents and total size together (for example, paginated UIs).
|
Note
|
On the /_size endpoint, counting is already implied, so adding ?count is redundant and behaves like plain /_size (exact count).
|
For count strategy details (including count=estimated and automatic fallback with filters), see Estimated Counts.
Behind the scene, this is implemented via the MongoDB cursor.skip() method;
The issue is that MongoDB queries with a large "skip" slow down linearly. As the MongoDB manual says:
The
cursor.skip()method is often expensive because it requires the server to walk from the beginning of the collection or index to get the offset or skip position before beginning to return result. As offset (e.g. pageNumber above) increases,cursor.skip()will become slower and more CPU intensive. With larger collections,cursor.skip()may become IO bound.
That is why the MongoDB documentation section about skips suggests:
Range queries can use indexes to avoid scanning unwanted documents, typically yielding better performance as the offset grows compared to using
skip()for pagination.
How it works
If the request contains the query parameter ?cache, then the query cursor used to retrieve the pagesize documents is cached. This allows to cache up to batchSize documents.
cache also works without explicitly setting page and pagesize: RESTHeart applies default values (page=1, pagesize=default-pagesize).
A subsequent request, on the same collection, and with the very same filter, sort, hint, etc. parameters can reuse the cached cursor, avoiding the need to query MongoDB, and speeding up the request.
count is handled separately from the cached page data. If a request uses ?cache&count, only the document page retrieval can hit the cache; the count is still computed for each request.
count=estimated only changes the counting strategy. It does not change cache behavior.
|
Note
|
as with any caching system, the performance gain comes at a price. The cached documents pages can be obsolete, since cached documents could have been modified or deleted and new documents could have been created. |
Configuration
The following configuration applies on caching
mongo:
# get collection cache speedups GET /coll?cache requests
get-collection-cache-size: 100
get-collection-cache-ttl: 10_000 # Time To Live, default 10 seconds
get-collection-cache-docs: 1000 # number of documents to cache for each request| parameter | description | default value |
|---|---|---|
|
the maximum number of cached cursors |
100 |
|
the time in milliseconds that an cursor is cached before it’s deleted |
10000 (10 seconds) |
|
the number of documents to cache per each query (must be >= |
1000 |
Results
The issue 442 on github, has the following performance results on a collection with 6+ millions documents.
Without caching (total time = ~12 seconds):
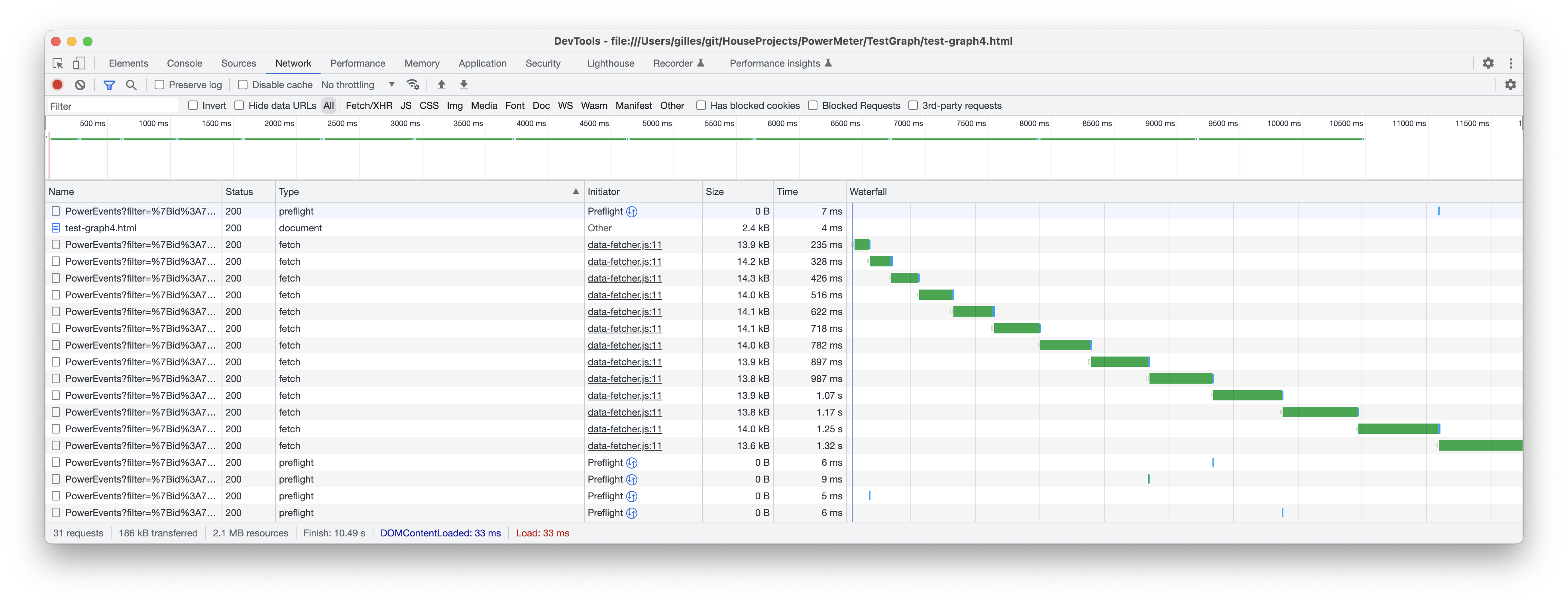
With caching (total time = ~2 seconds):

Cache consistency with transactions
To make sure that requests using caching return consistent data, transactions can be used, since the isolation property of transactions guarantees consistency.
Create a session
cURL
curl -i -X POST "[RESTHEART-URL]/_sessions" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http POST "[RESTHEART-URL]/_sessions" \
Authorization:"Basic [BASIC-AUTH]"JavaScript
fetch('[RESTHEART-URL]/_sessions', {
method: 'POST',
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => {
if (response.ok) {
const sessionUrl = response.headers.get('Location');
console.log('Session created:', sessionUrl);
return sessionUrl;
} else {
throw new Error(`HTTP ${response.status}`);
}
})
.catch(error => console.error('Error:', error));Start a transaction
cURL
curl -i -X POST "[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http POST "[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns" \
Authorization:"Basic [BASIC-AUTH]"JavaScript
fetch('[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns', {
method: 'POST',
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => {
if (response.ok) {
const txnUrl = response.headers.get('Location');
console.log('Transaction started:', txnUrl);
return txnUrl;
} else {
throw new Error(`HTTP ${response.status}`);
}
})
.catch(error => console.error('Error:', error));Get data in the transaction with caching
cURL
curl -i -X GET "[RESTHEART-URL]/coll?sid=11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0&txn=1&cache&page=3&pagesize=10" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http GET "[RESTHEART-URL]/coll" \
Authorization:"Basic [BASIC-AUTH]" \
sid==11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0 \
txn==1 \
cache==true \
page==3 \
pagesize==10JavaScript
fetch('[RESTHEART-URL]/coll?sid=11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0&txn=1&cache&page=3&pagesize=10', {
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => response.json())
.then(data => {
console.log('Retrieved cached data (page 3):', data);
})
.catch(error => console.error('Error:', error));Get the next page:
cURL
curl -i -X GET "[RESTHEART-URL]/coll?sid=11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0&txn=1&cache&page=4&pagesize=10" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http GET "[RESTHEART-URL]/coll" \
Authorization:"Basic [BASIC-AUTH]" \
sid==11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0 \
txn==1 \
cache==true \
page==4 \
pagesize==10JavaScript
fetch('[RESTHEART-URL]/coll?sid=11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0&txn=1&cache&page=4&pagesize=10', {
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => response.json())
.then(data => {
console.log('Retrieved cached data (page 4):', data);
})
.catch(error => console.error('Error:', error));Abort the transaction
cURL
curl -i -X DELETE "[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns/1" \
-H "Authorization: Basic [BASIC-AUTH]"HTTPie
http DELETE "[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns/1" \
Authorization:"Basic [BASIC-AUTH]"JavaScript
fetch('[RESTHEART-URL]/_sessions/11c3ceb6-7b97-4f34-ba3f-689ea22ce6e0/_txns/1', {
method: 'DELETE',
headers: {
'Authorization': 'Basic [BASIC-AUTH]'
}
})
.then(response => {
if (response.ok) {
console.log('Transaction aborted successfully');
} else {
throw new Error(`HTTP ${response.status}`);
}
})
.catch(error => console.error('Error:', error));